
Challenge #14 – Testing Santa’s Patience
Santa is gearing up for the holiday season by modernizing the gift list system at his North Pole headquarters.
Based on Rudolph’s expert recommendation, they are using Craft CMS to organize links to the various online suppliers and gifts.
Unfortunately, the content authoring aspect of the operation was delegated to the elves, who are not only technically challenged, but also dipped a bit too deeply into the eggnog.
The elves didn’t know anything about Craft CMS’s categories or sites or anything sensible, but instead created a Gifts section with two plain text fields: Supplier URL and Gift URI
They put the URL to the supplier in the Supplier URL field, and the URI path in the Gift URI field, so we have to combine the two together to make a complete URL to the gift that Santa can use.
Why did they do this? One cannot wonder the tangled ball of yarn that is the elve’s brains, especially fully saturated with alcohol.
But it gets worse.
Whilst copy-pasting the Supplier URLs and Gift URIs into Craft CMS, they didn’t always do a great job of it. Often they copied too much of each, so they overlap, and can’t be simply combined.
For example, look at this monstrosity:
Supplier URL: https://SantasHelper.com/es/products/gifts/
Gift URI: /es/products/gifts/three-foot-candy-cane
The final URL should look like this:
https://SantasHelper.com/es/products/gifts/three-foot-candy-cane
…but if we just combined the Supplier URL and Gift URI together, it would look like this:
https://SantasHelper.com/es/products/gifts//es/products/gifts/three-foot-candy-cane
What you need to do is write an algorithm that combines a Supplier URL together with a Gift URI in such a way that any overlapping suffix and prefix are merged together.
We’ll be doing this in PHP, but never fear if PHP isn’t your strong suit! We’ve provided a custom module in which you just have to implement a mergeUrlWithPath() function.
This GitHub repo contains a Craft CMS site that you can spin up with a single command, either locally or in the browser using a GitHub Codespace (see the readme file in the repo). The modules/Module.php file contains a mergeUrlWithPath() method that you can modify.
Because Santa is a perfectionist, he’s written a number of tests that your algorithm will have to pass before it’s considered acceptable. Santa wrote these tests using the fantastic Pest testing framework (with the aid of Mark Huot’s Craft Pest plugin).
To use it, with the project running, make a new terminal window by clicking on the + icon in the GitHub CodeSpaces terminal (or if you’re doing it locally, open up a new terminal however you like) and type:
make test
You’ll initially see something like this:
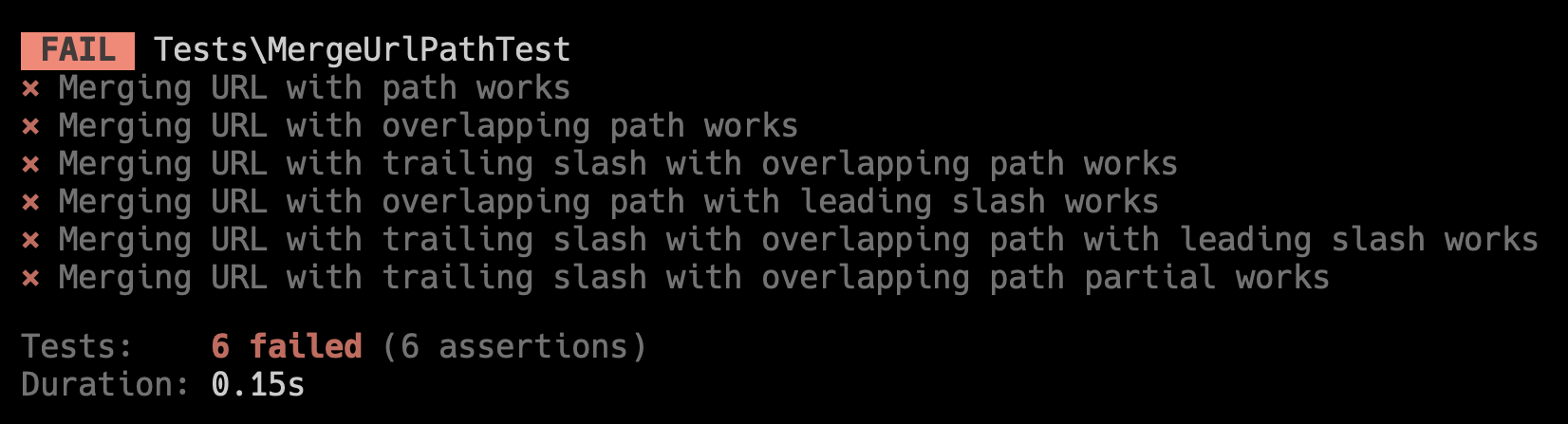
As you write your algorithm, your goal is to make it pass all of the tests… and congratulations! You’ve just taken your first steps into the world of Test Driven Development (TDD)!
Rules
Your solution should consist of a working mergeUrlWithPath() method that makes all tests pass.
Tips
Loop over strings, use recursion or otherwise, while watching out for pesky slashes.
Acknowledgements
Written by Andrew Welch & Ben Croker.
Solution
There are two general approaches we can take to solve this.
String Comparison
Loop over the characters in the path and compare them to the characters in the URL. Find the largest overlapping URL suffix and path prefix and remove the duplication before merging.
Segment Comparison
Break the URL and path into segments. Find the common segments at the end of the URL and start of the path and remove them before merging.
String Comparison
This approach involves comparing the URL suffix (the end of the string) with the path prefix (the start of the string) of varying lengths. What we’re looking for is the largest overlapping substring, which we will then remove from the path before merging it with the URL.
Since the URL and path may or not end and start with a slash, it is safest to first normalize them. We can do this by trimming a slash (from the right and the left, respectively, to avoid ending up with a double slashes) and then adding it back in.
$url = rtrim($url, '/') . '/';
$path = '/' . ltrim($path, '/');
Next comes our test for an overlap. We’ll wrap this in a for loop, starting with an empty overlap, and add a character from the path at each iteration. Any time the URL ends with the $test string, we’ll update the value of $overlap.
$overlap = 0;
for ($i = 0; $i < strlen($path); $i++) {
$test = substr($path, 0, $i);
if (str_ends_with($url, $test)) {
$overlap = $i;
}
}
Finally, we merge the URL with the part of the path after the overlap.
return $url . substr($path, $overlap);
Notice how our test string grows with each iteration. This results in n iterations where n is the length of the path.
An alternative, slightly more optimal solution would be to reverse the direction of the loop, and hence the test string. Starting from the full path, we’ll take a character off the end in each iteration. This allows us to break out of the for loop as soon as we find a match, meaning that n is the length of the overlap (and at most the length of the path).
$overlap = 0;
for ($i = strlen($path); $i > 0; $i--) {
$test = substr($path, 0, $i);
if (str_ends_with($url, $test)) {
$overlap = $i;
break;
}
}
The full solution is then as follows.
public function mergeUrlWithPath(string $url, string $path): string
{
$url = rtrim($url, '/') . '/';
$path = '/' . ltrim($path, '/');
$overlap = 0;
for ($i = strlen($path); $i > 0; $i--) {
$test = substr($path, 0, $i);
if (str_ends_with($url, $test)) {
$overlap = $i;
break;
}
}
return $url . substr($path, $overlap);
}
This passes all of of the provided tests.
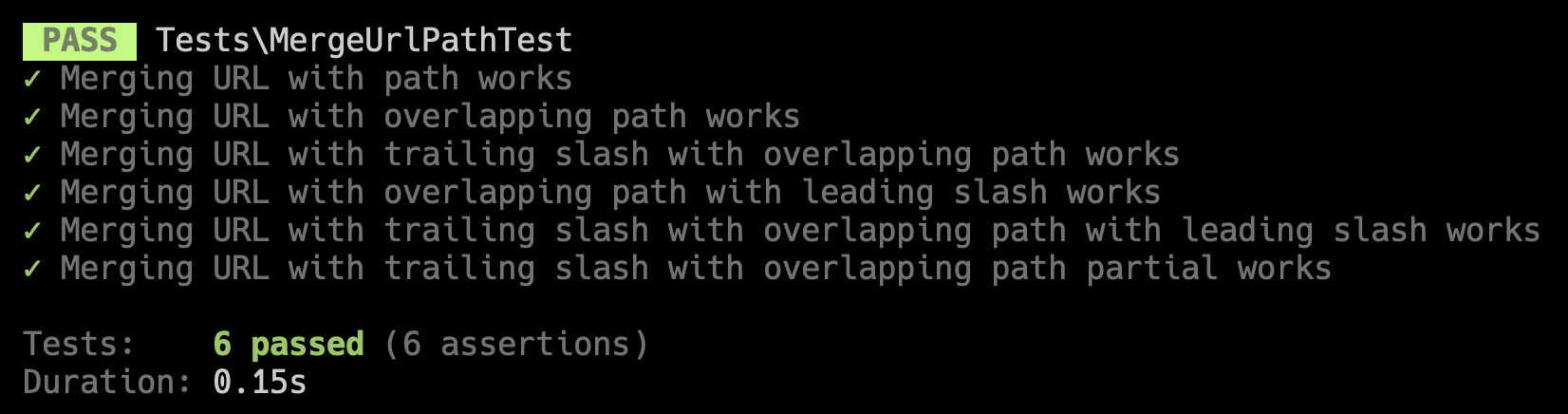
Ben Croker came up with a similar implementation using recursion.
Andrew Welch used a while loop, comparing the strings in a slightly different way.
Segment Comparison
This approach involves first breaking the URL and path into segments using a slash delimiter, finding the overlapping segments and then merging the unique segments back together. There are various ways of doing this and we’re going to refer to the submitted solutions rather than walk through any particular implementation.
Chris Sargeant delivered a solution that, while somewhat intricate, passes all tests.
Robin Gauthier and Lukas Jansen both leveraged PHP’s parse_url function to help parse the URL and path before performing their comparisons.
Kristian S. P. submitted a meticulously commented solution and even submitted a second, reads-more-like-a-German-sentence solution. Jawohl!
Chris Violette made use of Craft’s UrlHelper and FileHelper to help construct his solution.
Michael Thomas took advantage of collection methods to push and sanitise URI segments.
Edge-case Issues
All of the submitted solutions passed all tests, making everyone a winner!
The story, however, takes a turn for the worse.
There were some edge-case supplier URL and gift URI combinations in the mix that were incorrectly merged. This meant that some suppliers never received the gifts they were supposed to. Santa’s tests, it turns out, were fallible.
Only two of the submitted solutions [1, 2] managed to pass the following unforeseen “edge-cases”. All other solutions failed in one or more of them.
Supplier URL: 'https://SantasHelper.com/es'
Gift URI: 'essentials/gifts/3ft-cane'
Incorrect Result: 'https://SantasHelper.com/es/sentials/gifts/3ft-cane'
Supplier URL: 'https://SantasHelper.com/es/'
Gift URI: '/essentials/es/gifts/3ft-cane'
Incorrect Result: 'https://SantasHelper.com/es/essentials/gifts/3ft-cane'
Supplier URL: 'https://SantasHelper.com/es/gifts/'
Gift URI: '/gifts/3ft-cane'
Incorrect Result: 'https://SantasHelper.com/es/gifts/gifts/3ft-cane'
Supplier URL: 'https://SantasHelper.com/essentials/es/'
Gift URI: '/essentials/es/gifts/3ft-cane'
Incorrect Result: 'https://SantasHelper.com/essentials/es/essentials/es/gifts/3ft-cane'
Conclusion
Edge-cases are hard to catch ahead of time. This is one of the downfalls of test-driven-development. You may think you fully understand a problem before implementing it, but this does not rule out the value of writing tests after you’ve managed to get your initial tests to all pass.
It turns out that even Santa is “only human”. Hopefully he learns his lesson and demands properly formatted content from his suppliers next year!
Submitted Solutions
- Chris Sargeant
- Robin Gauthier
- Andrew Welch
- Kristian S. P.
- Chris Violette
- Lukas Jansen
- Ben Croker
- Michael Thomas
Solution submitted by Chris Sargeant on 12 December 2023.
public function mergeUrlWithPath(string $url, string $path): string {
// Split out the protocol if we can
$protosgs = array_filter(explode('://', $url));
$protocol = isset($protosgs[1]) ? $protosgs[0] : '';
// Remove any potential double slashes from the passed url
$cleaned = implode(
'/',
array_filter(
explode('/', isset($protosgs[1]) ? $protosgs[1] : $protosgs[0])
)
);
// Get the path segments of the passed path
$segments = array_filter(explode('/', $path));
// Search for a path match in the cleaned url
while (count($segments) > 0) {
$uri = implode('/', $segments);
if (str_ends_with($cleaned, $uri)) { // If we find it, clip it from the cleaned url and exit
$cleaned = str_replace($uri, '', $cleaned);
$segments = [];
} else {
array_pop($segments); // Remove a segment, try again
}
}
// Return a clean combination of the clipped (or not clipped) url and the path
return (!empty($protocol) ? "$protocol://" : '') . implode(
'/',
array_merge(
array_filter(explode('/', $cleaned)),
array_filter(explode('/', $path))
)
);
}Solution submitted by Robin Gauthier on 12 December 2023.
public function mergeUrlWithPath(string $url, string $path): string
{
$urlObj = parse_url($url);
//get array without empty value due to begining or trailling slash
$path = explode('/', trim($path, '/'));
$url = explode('/', trim($urlObj['path'], '/'));
//Find similar value in both array and keep keys
$intersect = array_intersect_assoc($url, $path);
if(!count($intersect)) {
//if no similar string, merge both array in one
$result = array_merge($url, $path);
} else {
//if similar value, loop in path to remove segment from the url
$result = $url;
foreach($path as $key=>$str) {
if(array_key_exists($key, $intersect)){
continue;
}
$result[] = $str;
}
}
//rebuild the url with all segments
return $urlObj['scheme'] . '://' .
$urlObj['host'] . '/' .
implode('/', $result);
}Solution submitted by Andrew Welch on 12 December 2023.
/**
* Merge the $url and $path together, combining any overlapping path segments
*
* @param string $url
* @param string $path
* @return string
*/
public static function mergeUrlWithPath(string $url, string $path): string
{
$overlap = 0;
$urlOffset = strlen($url);
$pathLength = strlen($path);
$pathOffset = 0;
while ($urlOffset > 0 && $pathOffset < $pathLength) {
$urlOffset--;
$pathOffset++;
if (str_starts_with($path, substr($url, $urlOffset, $pathOffset))) {
$overlap = $pathOffset;
}
}
return rtrim($url, '/') . '/' . ltrim(substr($path, $overlap), '/');
}Solution submitted by Kristian S. P. on 15 December 2023.
/**
* Returns the URL merged with the path, without an overlapping suffix and prefix.
*/
public function mergeUrlWithPath(string $url, string $path): string
{
$cutoffPoint = strpos($url, '://') + 3; // Where protocol ends, and rest of URL begins
$protocol = substr($url, 0, $cutoffPoint); // Split out the protocol for now
$url = substr($url, $cutoffPoint); // ... and get the rest of the URL
$stringToParse = $url . '/' . $path; // Merge path and url, and stick a slash between, just to be sure. The more (slashes) the merrier (Christmas)
$segments = explode('/', $stringToParse); // Split string by slashes keeping everything but, well, slashes
$segments = array_filter($segments, function($segment) { // Filter out empty elements caused by leading, trailing and superfluous ... slashes
return $segment !== '';
});
$combinedString = implode('/', array_unique( $segments )); // Remove all duplicates and glue them back together with – you guessed it! – slashes
return $protocol . $combinedString; // Tuck the protocol back on, and return the thing
}
/**
* (I couldn' help myself but writing a version that reads more like a sentence in German ...)
*/
public function mergeUrlWithPathConcise(string $url, string $path): string
{
$cutoffPoint = strpos($url, '://') + 3; // Where protocol ends, and rest of URL begins
$protocol = substr($url, 0, $cutoffPoint); // Split out the protocol for now
$url = substr($url, $cutoffPoint); // and get the rest of the URL
// Return whatever we get if we:
return $protocol . implode('/', // Glue url segments together with slashes
array_unique( // after having removed duplicate (overlapping) segments,
array_filter( // although only after filtering out empty "segments" that are leftovers from when we
explode('/', // split the input by slashes
( $url . '/' . $path ) // (Btw, by "input" I mean the url and path glued together with a slash)
), function($segment) {
return $segment !== ''; // P.S. This is how we know whether a value is empty or not
}) )
);
}Solution submitted by Chris Violette on 3 January 2024.
<?php
namespace modules;
use Craft;
use Craft\helpers\FileHelper;
use Craft\helpers\UrlHelper;
class Module extends \yii\base\Module
{
public function init(): void
{
Craft::setAlias('@modules', __DIR__);
parent::init();
}
/**
* Returns the URL merged with the path, without an overlapping suffix and prefix.
*/
public function mergeUrlWithPath(string $url, string $path): string
{
// Join the $url and $path to create the full URL
$fullUrl = $url . '/' . $path;
// Get the actual base URL, regardless of how those tricksy elves entered it
$baseUrl = UrlHelper::hostInfo($fullUrl);
// Get the actual path, no matter how the elves entered it
$rootRelativePath = UrlHelper::rootRelativeUrl($fullUrl);
// Normalize the path to remove any extra slashes
$rootRelativePath = FileHelper::normalizePath($rootRelativePath);
// Break the path up into its segments
$segments = collect(explode('/', $rootRelativePath));
// remove any duplicate path segments
$dedupedSegments = $segments->filter(function ($value, $key) use ($segments) {
// Keep the current path segment if it does not match the previous one
return $key === 0 || $value !== $segments->get($key - 1);
})->toArray();
// join up deduped segments
$dedupedRootRelativePath = implode('/', $dedupedSegments);
// Return the URL
return $baseUrl . $dedupedRootRelativePath;
}
}Solution submitted by Lukas Jansen on 6 January 2024.
public function mergeUrlWithPath(string $url, string $path): string
{
// Parse url to get the different components
$parsedUrl = parse_url($url);
// Get the scheme of the url (https://)
$scheme = isset($parsedUrl['scheme']) ? $parsedUrl['scheme'] . '://' : '';
// Get the host of the url (SantasHelper.com)
$host = isset($parsedUrl['host']) ? $parsedUrl['host'] : '';
// Get the path of the url
$parsedPath = isset($parsedUrl['path']) ? $parsedUrl['path'] : '';
// Remove starting and trailing slashes from parsedPath
$parsedPath = trim($parsedPath, '/');
// Make sure the parsedPath has a trailing slash to compare with the passed Path (if the parsedPath is not empty)
if ($parsedPath !== '') {
$parsedPath = "$parsedPath/";
}
// Check if the path (without leading slash) matches the parsedPath
if (str_starts_with(ltrim($path, '/'), $parsedPath)) {
// If it matches only add the passed Path and make sure it starts with a leading slash
$completePath = str_starts_with($path, '/') ? $path : "/$path";
} else {
// If it doesn't matches combine the parsedPath with the passed path (without leading slash as we already forced this on the parsedPath)
$completePath = '/' . $parsedPath . ltrim($path, '/');
}
// combine all the url parts;
return "$scheme$host$completePath";
}Solution submitted by Ben Croker on 8 January 2024.
/**
* Returns the URL merged with the path, without an overlapping suffix and prefix.
*/
public function mergeUrlWithPath(string $url, string $path): string
{
$url = rtrim($url, '/') . '/';
$path = '/' . ltrim($path, '/');
$overlap = $this->findOverlap($url, $path);
return $url . substr($path, $overlap);
}
/**
* Recursively finds and returns an overlap between the URL and path.
*/
private function findOverlap(string $url, string $path): string
{
if (strlen($path) === 0) {
return 0;
}
if (str_ends_with($url, $path)) {
return strlen($path);
}
return $this->findOverlap($url, substr($path, 0, -1));
}Solution submitted by Michael Thomas on 10 January 2024.
public function mergeUrlWithPath(string $url, string $path): string
{
// strip https:// or http:// from our url and remember it:
$strippedUrl = parse_url($url)['host'] . parse_url($url)['path'];
$scheme = parse_url($url)['scheme'] . '://';
$explodedUrl = collect([]);
$explodedPath = collect([]);
// Explode into arrays
foreach(explode('/', $strippedUrl) as $part) {
$explodedUrl->push($part);
}
foreach(explode('/', $path) as $part) {
$explodedPath->push($part);
}
$sanitisedUrl = $explodedUrl->filter(function(string $value) { return $value !== ''; })->values();
$sanitisedPath = $explodedPath->filter(function(string $value) { return $value !== ''; })->values();
$mergedUrl = $sanitisedUrl->merge($sanitisedPath)->unique()->implode('/');
//return $scheme . $mergedUrl->implode('/');
return $scheme . $mergedUrl;
}